Scan your Python agent code
Verify requirements
Check that Flint AI CLI and OpenGrep are installed:
See OpenGrep installation for more options.
Install OpenGrep
Install OpenGrep
Install Flint AI CLI
Install Flint AI CLI
Scan your agent
Point to your agent directory and launch the scan:Results are saved to
Flint AI Scan only analyzes Python files with supported framework imports. See supported frameworks →
scan_<timestamp>.json. See Scan results for details on understanding findings and severity scores.Clean scan
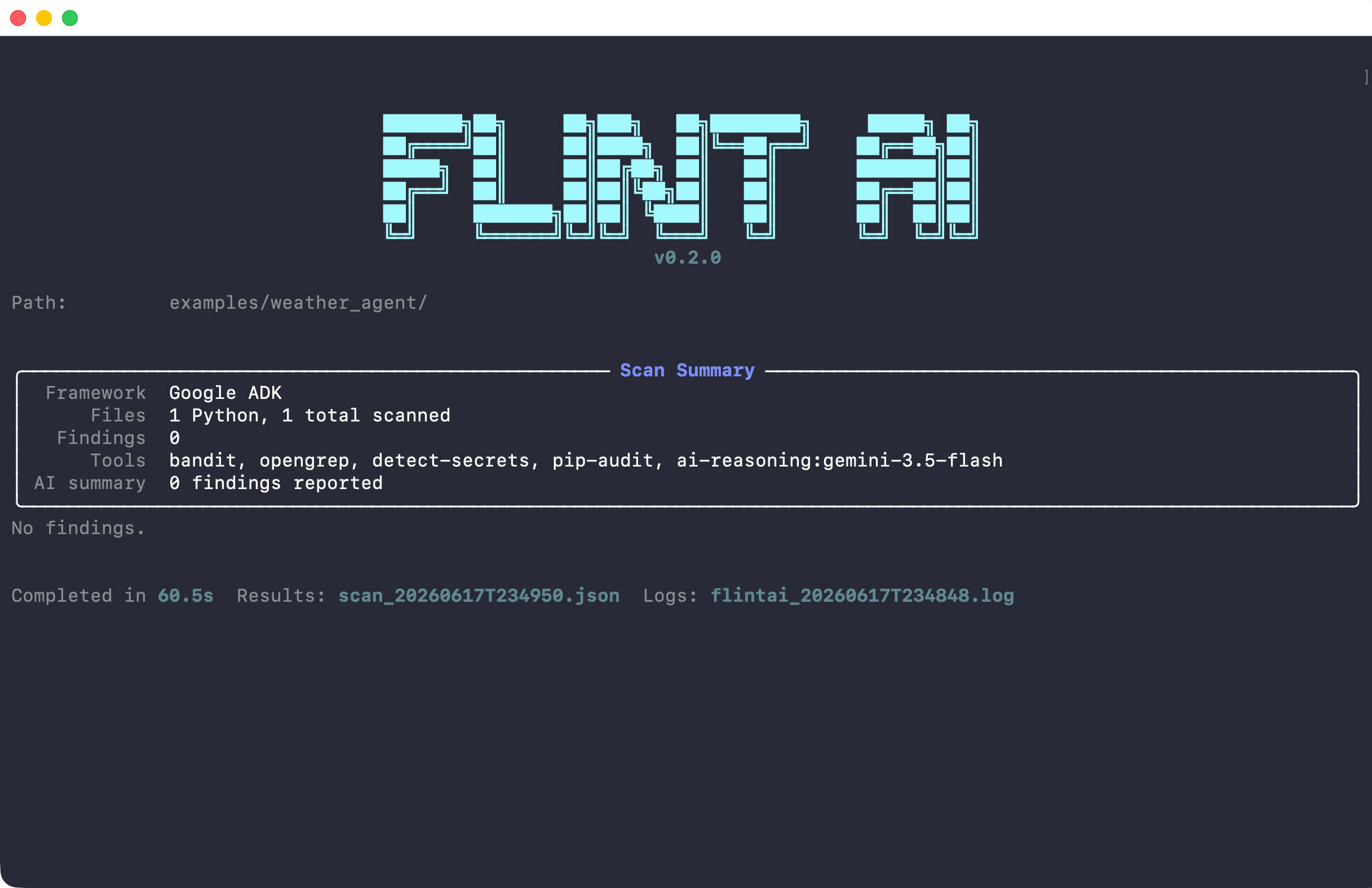
Scan with findings
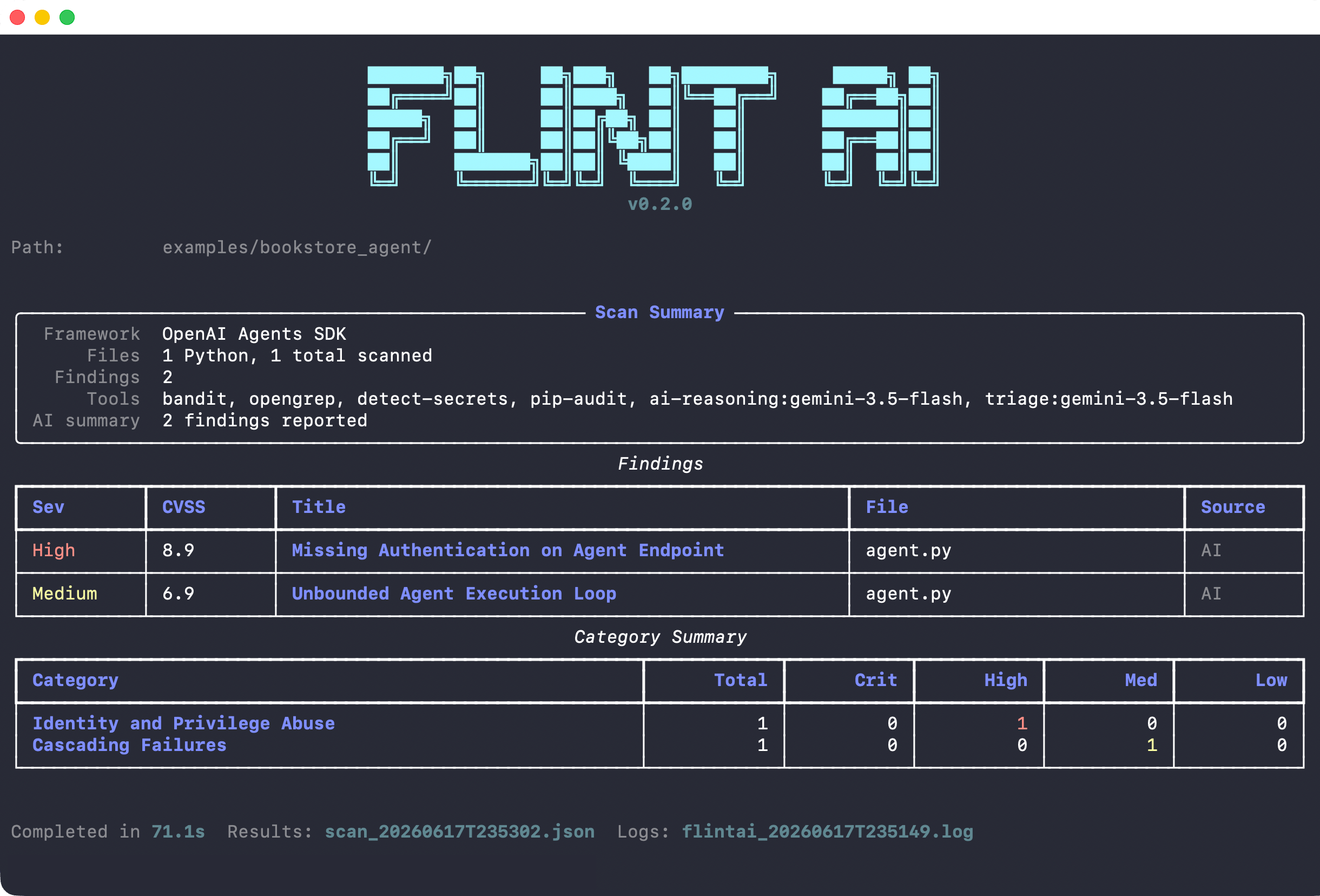
- High severity (CVSS 9.0): Missing authentication on agent endpoint
- Medium severity (CVSS 6.9): Unbounded agent execution loop
Next steps
Issues found?
Understand severity scores and what needs fixing before deployment
How scanning works
Learn how AI reasoning finds real issues and filters noise
Eval agent behavior
Get a 0.0-1.0 reliability score for runtime behavior